
SDM workflow I - Data
Occurence records
Species distribution modeling is only possible when some data on the occurrence of a species have been determined on-site by experts. In the map below you can see findings of Aglais caschmirensis in Pakistan from the dataset you will use for the student tutorial, you can find the whole dataset in ILIAS.
Full screen version of the map
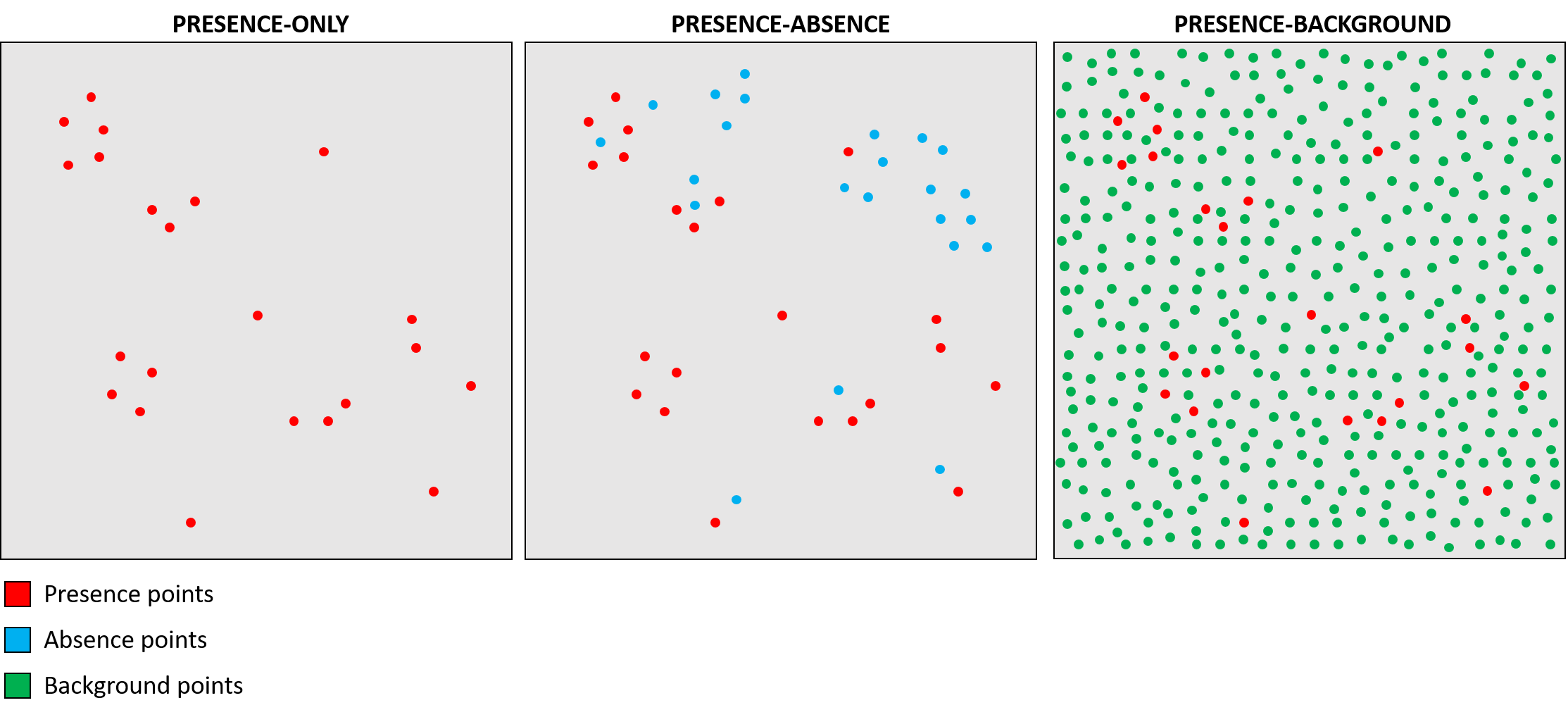
There are two ways in which data can be collected. Firstly, only the presence of a species can be recorded, these data are referred to as presence-only data. Secondly, both the presence and absence of a species can be determined, these data are referred to as presence-absence data. Presence-only data consists of observations or records of species presence at specific locations. Presence-only data is most commonly used, as data on species absence are often unavailable or challenging to obtain. Modeling with presence-only data aims to infer the environmental conditions associated with species occurrence and predict suitable habitats based on the known occurrences.
Presence-absence data includes both presence and absence records of the species at different locations. These data indicate where the species is found (presence) as well as where it is not found (absence). Presence-absence data provides more information compared to presence-only data as it allows modeling the relationships between species occurrence and environmental factors, considering both presence and absence as response variables. This type of data is useful for evaluating factors that influence the absence of a species. Especially for model evaluation absence data is often necessary. However often no information about a species absence is collected. And also absence data can be a lot more unreliable then presence data. As the concept “absence of evidence is not evidence of absence” is especially applicable to species that are hard to spot or moving in space.
Most modelling techniques originally were based on presence-absence data, but as these data is often not available or more unreliable, so called background points are used for modelling if no absence data is available.
Presence-background data is a variation of presence-only data where a random set of background points is selected. The background points represent the available habitat or the spatial extent where the species could potentially occur, they are supposed to represent the environmental conditions as completely as possible. This means that thousands of points get sampled depending on the size of the study area.
Environmental variables
Environmental variables or predictors used in species distribution modeling encompass a wide range of factors that influence species occurrence and habitat suitability. Climate data, such as temperature, precipitation, and seasonality, are commonly employed as key predictors due to their fundamental role in shaping ecological conditions. Remote sensing data, derived from satellites or aerial imagery, provide valuable information on vegetation indices and topographic characteristics. These data sources enable the assessment of habitat structure, fragmentation, and productivity. Additionally, landscape data like land use/land cover classifications can help to reflect on the human impact in the potential habitat. By integrating multiple environmental variables, species distribution models can elucidate the complex interactions between species and their environment, enabling more accurate predictions and informed conservation decisions.
The choice of environmental variables is not trivial, if variables are selected by the user that do not represent the species, the model cannot predict its distribution in a meaningful way.