Merging
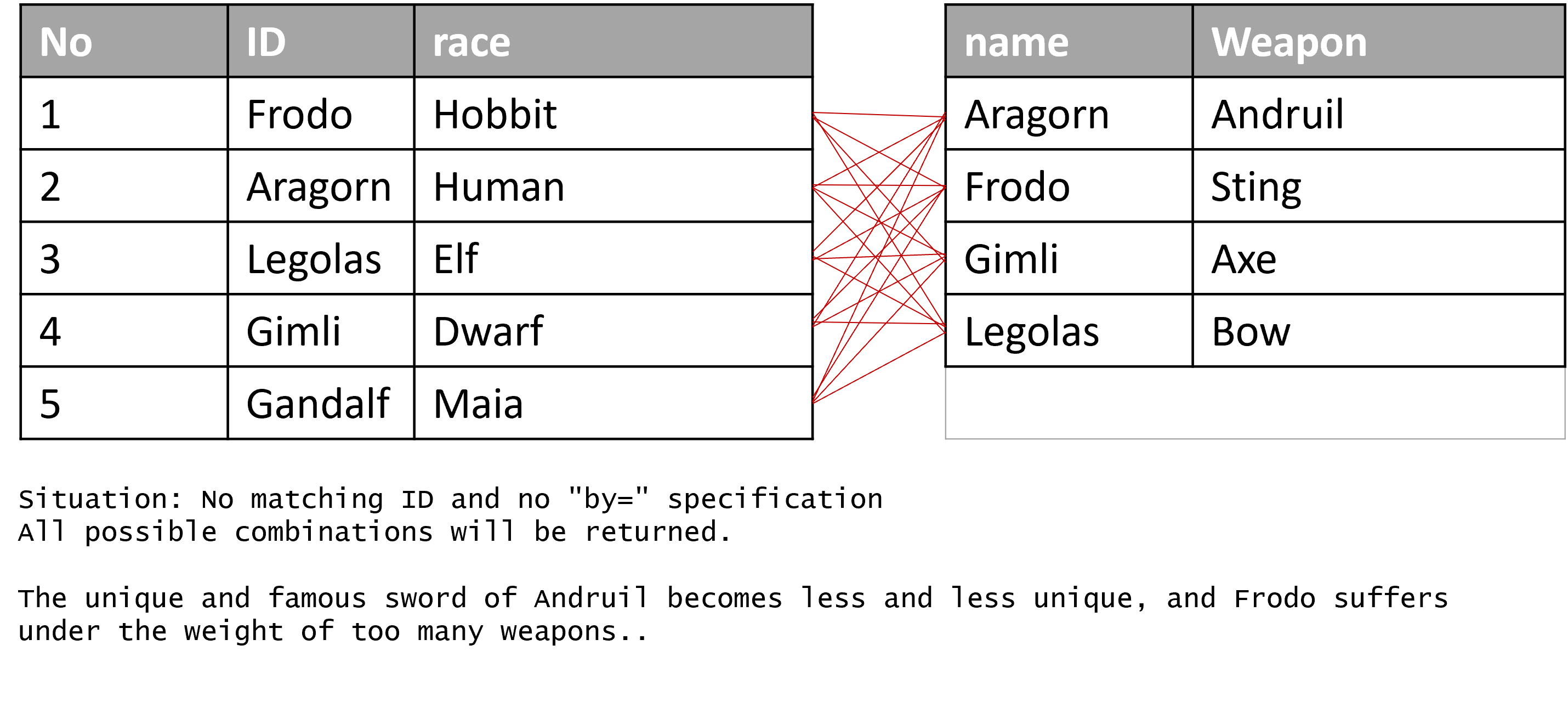
To merge data frames based on identifiers rather than the order of the rows, we utilize the merge() function. When merging two data frames, it’s essential to designate the column that contains the identifiers for matching by using the by= argument. This is a crucial step; failing to specify the column can result in R handling the task in one of two ways:
-
If there is a column with the same name in both data frames, R will automatically use that column for merging. However, it is not always certain that this column contains matching information across both data frames, which can lead to erroneous results.
-
Without a specified matching column, R performs a Cartesian product of the data frames, repeating each row in the first data frame with every row in the second, as illustrated here:
In this example, we use the values of the column Z to merge the two data frames:
dfc <- merge(df1, df2, by = "Z")
dfc
## Z X.x Y.x X.y Y.y
## 1 A 1 1.4 100 14
## 2 B 2 2.5 500 55
## 3 C 3 3.6 200 25
## 4 D 4 4.0 400 40
## 5 E 5 5.5 300 36
Since both data frames have identical column names, X and Y is added to the
column names in the resulting data frame to indicate if the column is from the
first (i.e. X) or second (i.e. Y) data frame. You can easily rename the columns
using the colnames function.
If the columns which should be used for mergin have different names, no problem: just supply the column names separately for the first (i.e. X) and second (i.e. Y) data frame:
colnames(df2) <- c("H", "I", "J")
dfc <- merge(df1, df2, by.x = "Z", by.y = "J")
dfc
## Z X Y H I
## 1 A 1 1.4 100 14
## 2 B 2 2.5 500 55
## 3 C 3 3.6 200 25
## 4 D 4 4.0 400 40
## 5 E 5 5.5 300 36
Since not only the names of the columns used for merging but all column names are different, no X or Y is added in the output column names.
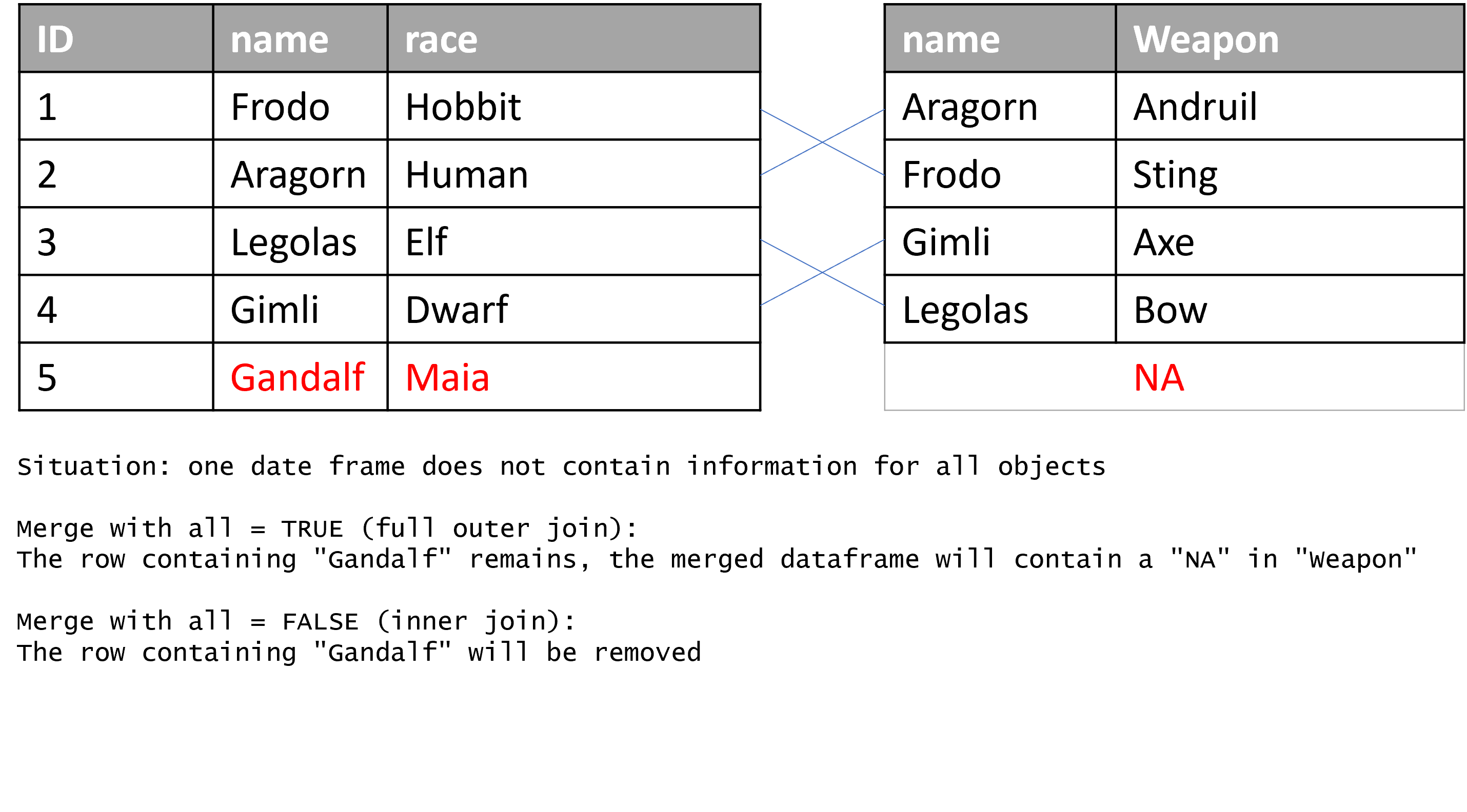
Be cautious: by default, only the identifiers present in both data frames are retained in the merged data frame. You can modify this behavior by setting all=TRUE, which includes all identifiers from both data frames, not just those that appear in both. If you wish to keep all records from the first data frame regardless of a match in the second, set all.x=TRUE. Conversely, use all.y=TRUE to preserve all records from the second data frame when they don’t have a match in the first. Tip: The techniques you learned in Unit 04 can be useful in identifying these missing values