
| LM | Randomly good |
In this lesson, we will predict spatial features with machine learning techniques and use random validation methods. Don’t let the name fool you: The method is not randomly selected, rather the method uses randomized subsamples to cross-validate the accuracy of the machine learning technique. Our goal is to determine the presence or absence of buildings in the southern part of Marburg, Hesse. To accomplish this, we will use a machine learning approach together with a few data sources – digital orthophotos (DOPs) as well as the digitized polygons that we created in Unit 1 (one class for buildings and another class for everything else).
We want to create a model that can distinguish between pixels from a building and those that belong to their surroundings. To do this we need the bands of the DOP as well as several indices that are calculated based on them. You can simply use the ones we created in Unit 1.
Our area of interest (AOI):
Full screen version of the map
Random forest – the basics
To accomplish this task, we will use a random forest machine learning approach. Random forests can be used for both regression or classification tasks, the latter of which is particularly relevant in environmental remote sensing. As is the case with every machine learning method, the random forest model learns to recognize patterns and structures in the data on its own.
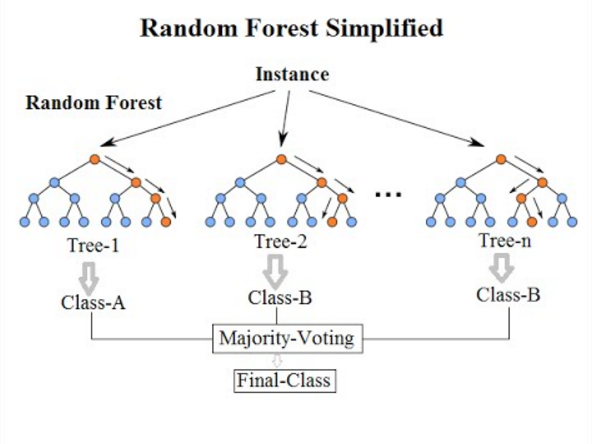
Image: Simplification of how random forest classifies data during training. Venkata Jagannath [CC BY-SA 4.0] via wikipedia.org
{kind=link}
The random forest algorithm learns about the data by building many decision trees – hence, the name “forest”. For classification tasks, the algorithm takes an instance from the training dataset and each tree (again, there are many) classifies that instance into a class, as in the above diagram. Ultimately, the instance is assigned to the class that is the outcome of the most trees. Of course, this is an oversimplified description of how it really works. If you are interested in the theory and math behind how the algorithm truly works, please see the paper by Breiman (linked below).
Since the random forest algorithm requires training data, it is a supervised learning method. This means that we, as users, must tell the algorithm what it is supposed to predict. In our case, in order for the algorithm to classify building pixels correctly, the training data must include and be labeled with different categories or land cover classifications (i.e., field, building, forest, water).

Image: Machine Learning. Chitra Sancheti [CC BY-SA 4.0] via wikimedia.org
{kind=link}
We also need a validation strategy that tells us how well the model performs. We will use one of the most popular methods for validating model quality: cross-validation. The goal is to test how well the model generalizes on an independent dataset. For example, if we perform a 5-fold cross-validation, the entire dataset available to the model is split five times (randomly) into a training and a validation dataset. Then the model is trained five times with each training dataset and its quality is determined with the randomly selected validation dataset.

Image: Random cross-validation. Gufosowa [CC BY-SA 4.0] via wikipedia.org
#/media/File:K-fold_cross_validation_EN.svg){kind=link}
Unit 3 slides
Additional resources
Breiman, Leo (2001). “Random Forests”. Machine Learning. 45 (1): 5-32. https://doi.org/10.1023/A:1010933404324.
Machine learning
Here are several videos that introduce the enormous field of machine learning, in general, as well as the specific algorithm that we will use in this course, random forest. In addition to these videos, we encourage you to do your own research, as there are many great tutorials on the Internet for all types of learners.
A Gentle Introduction to Machine Learning (12:44):
Decision Trees (17:21):
Decision Trees Part 2 - Feature Selection and Missing Data (5:15):
Random Forests Part 1 - Building, Using and Evaluating (9:53):
Random Forests Part 2 - Missing data and clustering (11:52):
Random Forests in R (15:09):
Machine Learning Fundamentals - Cross Validation (6:04):