
| LM | Spatially good |
Resilient spatial predictions require appropriate selection and validation strategies that are tailored for spatial data.
There are some special features of spatial data that must be taken into account when selecting methods for forecasting. Spatial data cannot be treated like other datasets. As we saw in Unit 1, proximity does not necessarily have anything to do with context. Nevertheless, proximity is an important issue when we try to validate spatial models.
In the last exercise, we created a random forest model and validated it using a standard 10-fold random cross-validation (CV). For this type of CV, the dataset was split randomly. Even though this type of CV is standard in many studies, this process ignores where exactly the pixels are in space when it selects the validation and training datasets. This can result in pixels from a polygon being used for both training and validation. But is it bad if pixels from the same polygon are in the training and validation datasets?
Yes, because this leads to the data being spatially autocorrelated. What does spatial autocorrelation mean? It means that the dataset that should be used to validate the model is too similar to the training dataset, and that the model based on these training and validation datasets will be estimated to be significantly better than it actually is (see e.g. Ploton et al. 2020).
So we need a spatial validation model that is better suited for spatial data. To tackle this problem, we will drop the random CV and replace it with a spatial CV, namely Leave-Location-Out (LLO).
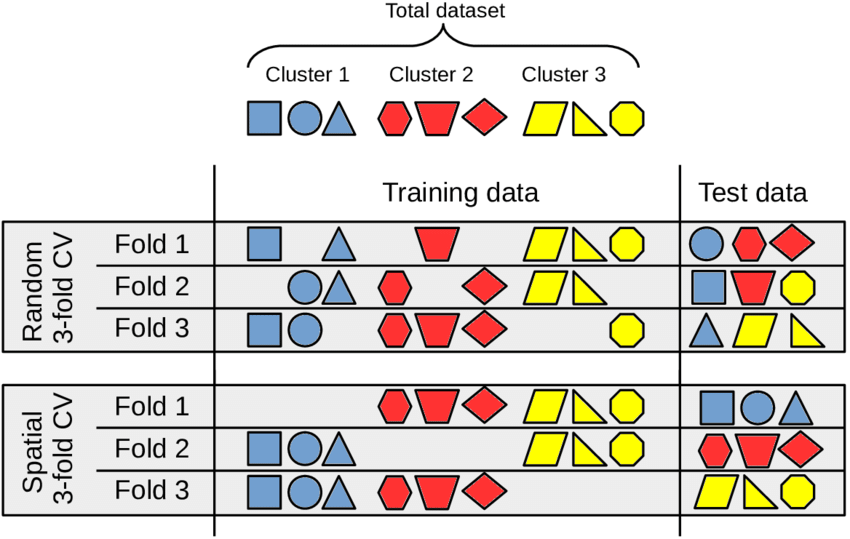
The function CreateSpacetimeFolds from the package CAST implements LLO CV. It does so by grouping the pixels in a dataframe according to the polygon, in which they are located. In the process, only whole locations (polygons) are used for either validation or training.
Ultimately, this better prevents us from assuming that the model is better than it actually is.
LLO CV reduces spatial autocorrelation, which is critical to finding out how accurate our model is. But we want efficient models as well, so we will also perform a spatial variable selection. Variable selection is a process that selects only the most relevant predictors from all of our variables and disregards all of the rest. For the spatial variable selection, we will use another function from the same package: forward feature selection (FFS). In a nutshell, FFS trains models using every possible combination of 2 predictors and keeps the model with the best performance. Then, it continues to add additional variables (3, 4, 5, etc.) until the performance stops improving. Read more about FFS, e.g. here or here.
Please familiarize yourself with LLO and FFS by reading the corresponding articles.
Further reading
Meyer H, Reudenbach C, Hengl T, Katurji M, Nauss T (2018) Improving performance of spatio-temporal machine learning models using forward feature selection and target-oriented validation. Environmental Modelling & Software 101: 1-9. https://doi.org/10.1016/j.envsoft.2017.12.001.
Meyer H, Reudenbach C, Wöllauer S, Nauss T (2019) Importance of spatial predictor variable selection in machine learning applications – Moving from data reproduction to spatial prediction. Ecological Modelling 411: 108815.https://dx.doi.org/https://doi.org/10.1016/j.ecolmodel.2019.108815
Meyer, H., & Pebesma, E. (2021). Predicting into unknown space? Estimating the area of applicability of spatial prediction models. Methods in Ecology and Evolution, 12, 1620-1633. https://doi.org/10.1111/2041-210X.13650
Still have questions?
We highly recommend the following talks, which addresses the issues in greater depth:
- Hanna Meyer: “Machine-learning based modelling of spatial and spatio-temporal data” (53:24)
- Hanna Meyer: “Estimating the area of applicability of spatial prediction models” (22:11)