Spotlight: Land-cover Classification
Classifications aim in grouping pixel values into homogeneous categories. The categories can be defined a priori or posteriori whichever supervised or unsupervised classification model is used.
Unsupervised land-cover classification
An unsupervised land-cover classification uses unlabeled input data that is grouped into homogeneous classes. Once the classes have been computed, the user assigns a reasonable land-cover type to each class (if possible) posteriori.
Such classifications generally require at least three steps:
- Compilation of a comprehensive input dataset containing one or more raster layers.
- Classification of the unlabeled input dataset into n clusters based on the homogeneity of the pixel values. A typical classification model for this step is the k-means cluster algorithm.
- Assignment of land-cover types to the individual clusters by the remote sensing expert. The same land-cover type class can be assigned to more than one cluster.
The assignment of land-cover types to the clusters requires some knowledge about the actual land-cover distribution in the respective observation area. If the selected land-cover types and the clusters do not match, one can change and extend the input data set or use a different setting for the clustering algorithm or adjust the detail level of the land-cover typology.
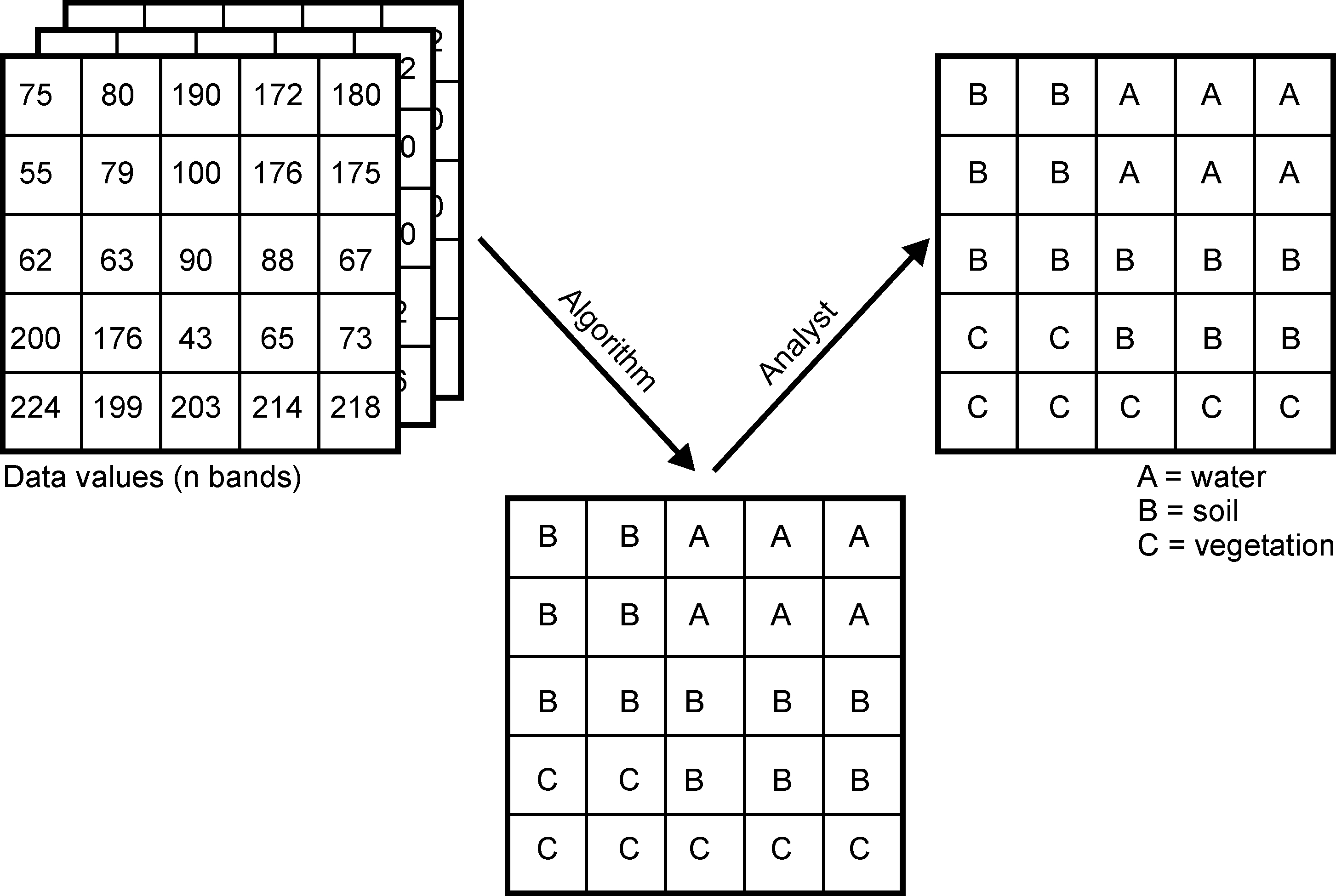
Supervised land-cover classification
A supervised land-cover classification uses a limited set of labeled training data to derive a model which is used to predict the respective land-cover in the entire dataset. Hence, the land-cover types are defined a priori and the model tries to predict these types based on the similiarity between the properties of the training data and the rest of the dataset.
Such classifications generally require at least five steps:
- Compilation of a comprehensive input dataset containing one or more raster layers.
- Selection of training areas, i.e. subsets of input datasets for which the land-cover type is known by the remote sensing expert. Knowledge about the land-cover can be derived e.g. from own or third party in situ observations, management information or other remote sensing products (e.g. high resolution aerial images).
- Training of a model using the training areas. For validation purposes, the training areas are often further divided into one or more test and training samples to evaluate the performance of the model algorithm.
- Application of the trained model to the entire dataset, i.e. prediction of the land-cover type based on the similarity of the data at each location to the class properties of the training dataset.
Please note that all types of classifications require a thorough validation which will be in the focus of upcomming course units.
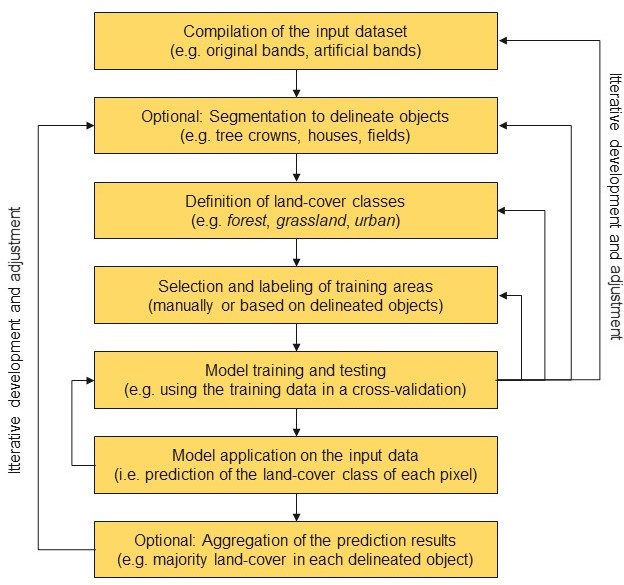
The following illustration shows the steps of a supervised classification in more detail. The optional segmentation operations are mandatory for object oriented classifications which do not only rely on the values of each individual raster cell in the input dataset but also consider the geometry of objects. To delineate individual objects like houses or tree crowns, segmentation algorithms are used which consider the homogeneity of the pixel values within their spatial neighborhood.