
{kind=link}
| EX | U-Net |
Now we are ready to define a U-Net. Don´t get frightened of by the length of this code section. Even if it might look scary at first glance the structure of the individual layers is actually quite repetitive.
#U-Net
# function to build a U-Net
# of course it is possible to change the input_shape
get_unet_128 <- function(input_shape = c(128, 128, 3),
num_classes = 1) {
inputs <- layer_input(shape = input_shape)
# 128
down1 <- inputs %>%
layer_conv_2d(filters = 64,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 64,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
down1_pool <- down1 %>%
layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2))
# 64
down2 <- down1_pool %>%
layer_conv_2d(filters = 128,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 128,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
down2_pool <- down2 %>%
layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2))
# 32
down3 <- down2_pool %>%
layer_conv_2d(filters = 256,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 256,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
down3_pool <- down3 %>%
layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2))
# 16
down4 <- down3_pool %>%
layer_conv_2d(filters = 512,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 512,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
down4_pool <- down4 %>%
layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2))
# # 8
center <- down4_pool %>%
layer_conv_2d(filters = 1024,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 1024,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
# center
up4 <- center %>%
layer_upsampling_2d(size = c(2, 2)) %>%
{
layer_concatenate(inputs = list(down4, .), axis = 3)
} %>%
layer_conv_2d(filters = 512,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 512,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 512,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
# 16
up3 <- up4 %>%
layer_upsampling_2d(size = c(2, 2)) %>%
{
layer_concatenate(inputs = list(down3, .), axis = 3)
} %>%
layer_conv_2d(filters = 256,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 256,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 256,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
# 32
up2 <- up3 %>%
layer_upsampling_2d(size = c(2, 2)) %>%
{
layer_concatenate(inputs = list(down2, .), axis = 3)
} %>%
layer_conv_2d(filters = 128,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 128,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 128,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
# # 64
up1 <- up2 %>%
layer_upsampling_2d(size = c(2, 2)) %>%
{
layer_concatenate(inputs = list(down1, .), axis = 3)
} %>%
layer_conv_2d(filters = 64,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 64,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu") %>%
layer_conv_2d(filters = 64,
kernel_size = c(3, 3),
padding = "same") %>%
layer_activation("relu")
# 128
classify <- layer_conv_2d(
up1,
filters = num_classes,
kernel_size = c(1, 1),
activation = "sigmoid"
)
model <- keras_model(inputs = inputs,
outputs = classify)
return(model)
}
Note
The creation of a Convolutional Neural Network tends to be more computationally intensive compared to the Random Forest. For this reason, it is likely that the example shown here of a U-Net,
which is trained with about 1713 training images over 10 epochs, will probably require several hours on your CPU to train. Accordingly, it is a good idea to run the training process at a time when you do not need your computer (e.g. over night).
The main reason for the calculation time is the large number of trainable parameters (just take look when you print out the variable unet_model). Of course, there are some ways to shorten the calculation time.
However, these approaches must be modified with care, as they will affect the accuracy of the model. Some suggestions that can be easily modified from the existing example would be:
- Changing the input size. Results in the spatial context being reduced, thus the generalisability of the model may be degraded and the training process may also become poor.
- Decrease the batch size. Causes the number of input data per run to be reduced.
- Reduction of the number of training data. Either the training process takes place on a smaller image section or the ratio of training and validation data have to be changed.
- If you have a dedicated GPU, TensorFlow can also be installed on it. In this way, the large number of parameters can be calculated side by side, to put it simply. This approach makes the training much faster, but for beginners this approach is not recommended, as the installation is much more difficult. Take a look.
- Increasing the learning rate could make your U-Net converge faster, but it is also possible that your U-Net is not able to learn something.
- Shortening the number of epochs.
Model training
The actual modelling is rather short, we load the network,compile and train it.
unet_model <- get_unet_128()
# compile the model
unet_model %>% compile(
optimizer = optimizer_adam(learning_rate = 0.0001),
loss = "binary_crossentropy",
metrics = "accuracy"
)
# train the model
hist <- unet_model %>% fit(
training_dataset,
validation_data = validation_dataset,
epochs = 10,
verbose = 1
)
# save the model
unet_model %>% save_model_hdf5(file.path(envrmt$path_models, "unet_buildings.hdf5"))
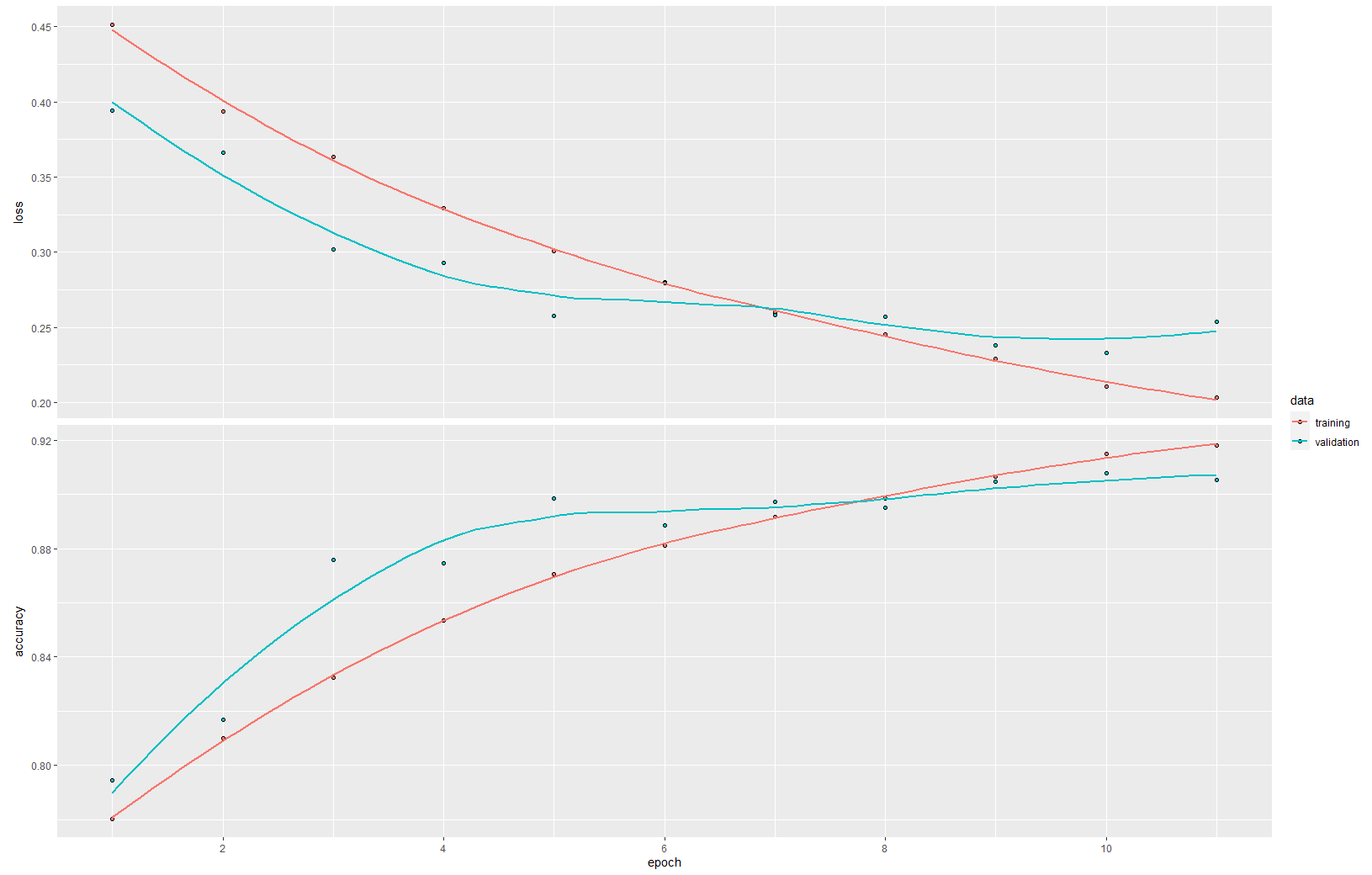
plot(hist)
One of the first things you will notice when your fitting your model is this type of line plot. The upper plot shows the progress of the loss. Since we would like to reduce the loss it should continually decrease. In contrast to the loss the accuracy of the model should increase. If you have such a converging plot your model is currently learning. But it is important that not only the training loss and accuracy is improving but also the validation loss/accuracy. Otherwise your model tends under- or overfit.
Download as Image or view full screen version
{kind=link}
Comments?
You can leave comments under this Issue if you have questions or remarks about any of the code chunks that are not included as gist. Please copy the corresponding line into your comment to make it easier to answer the question.